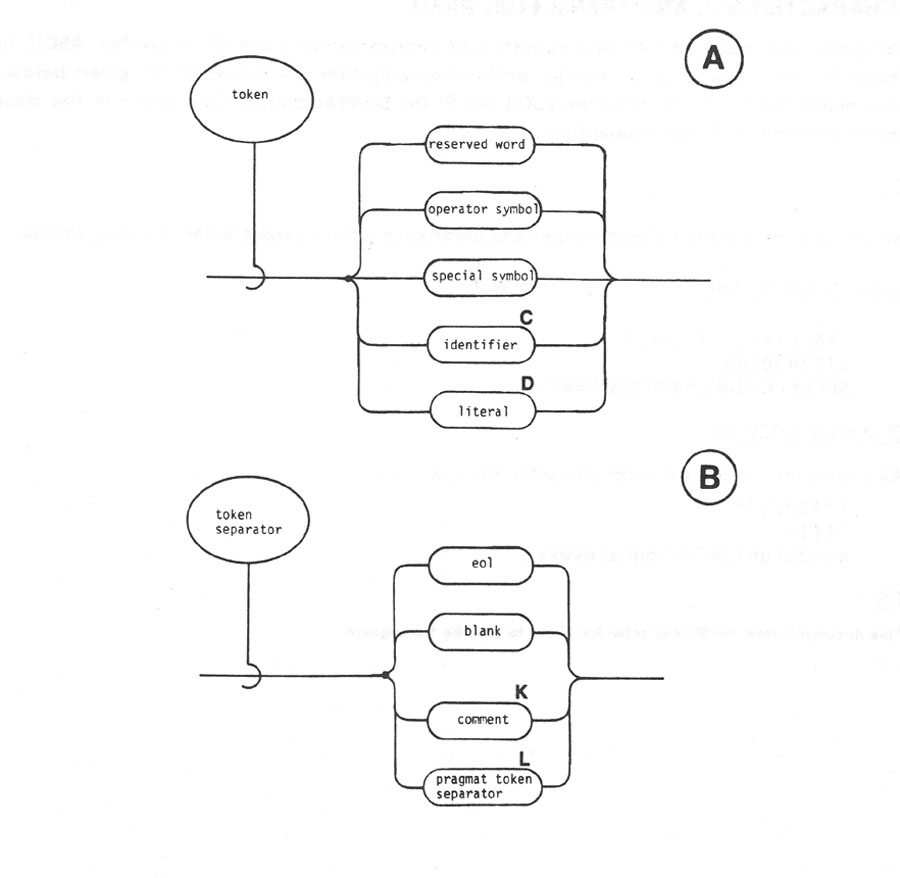
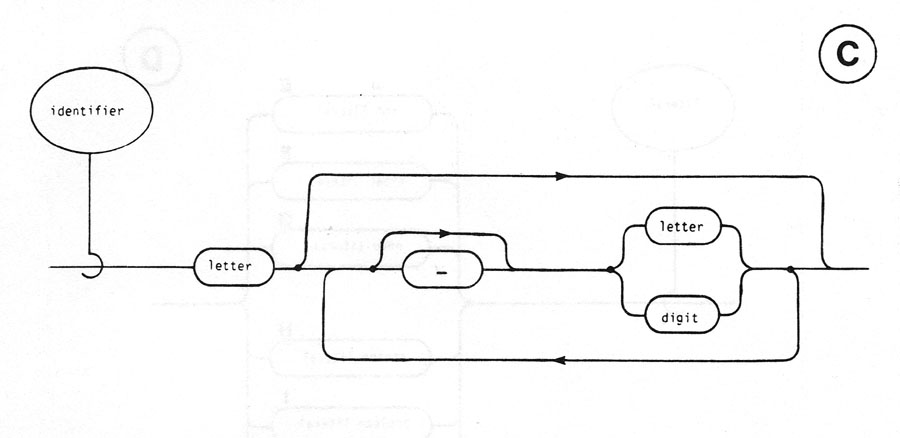
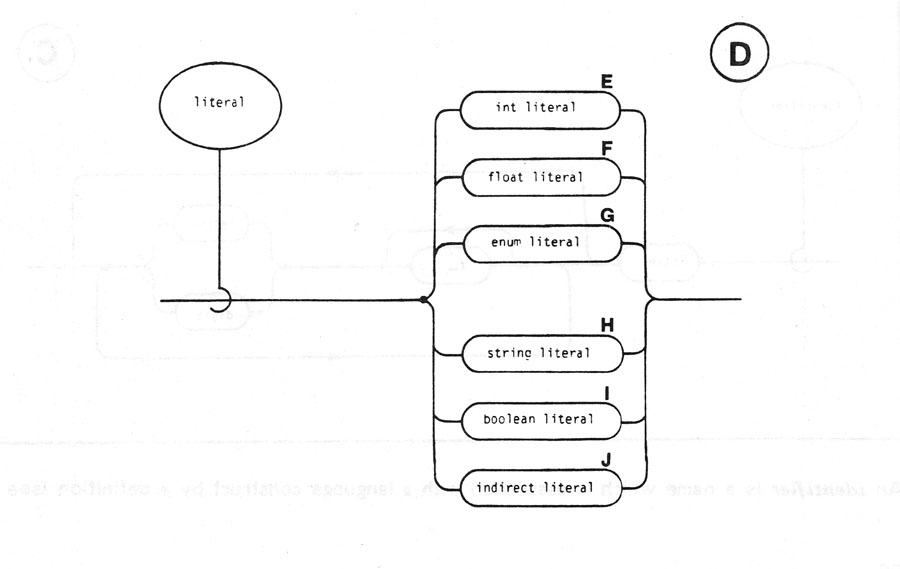
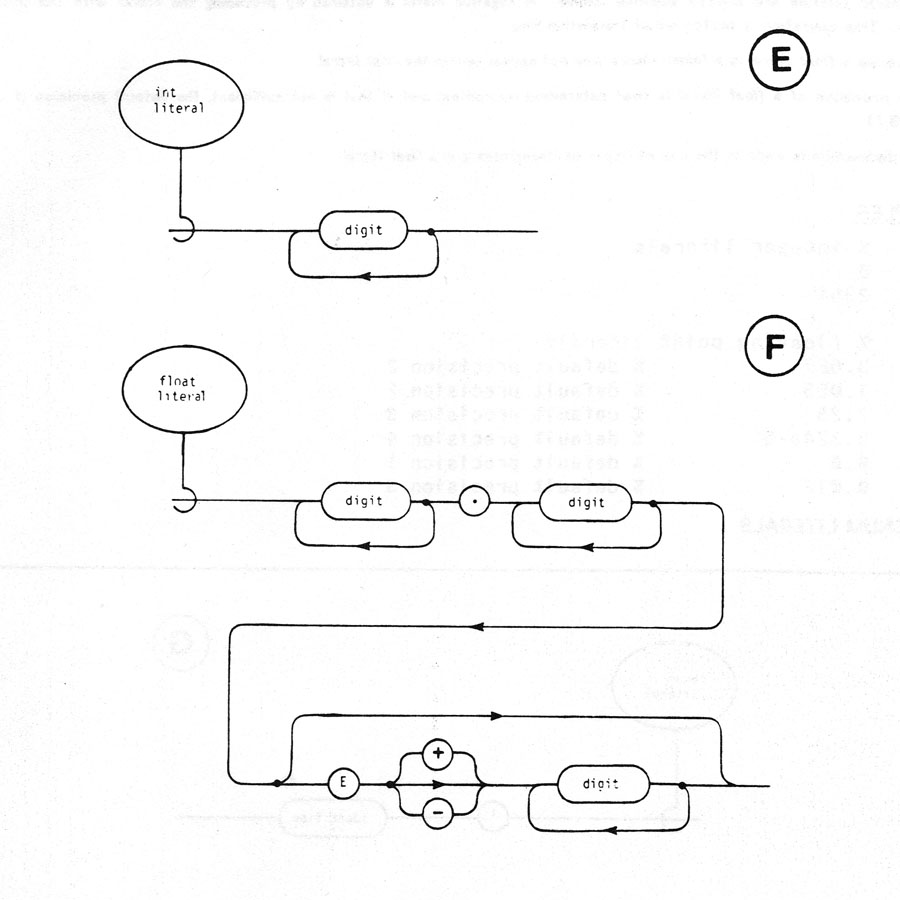
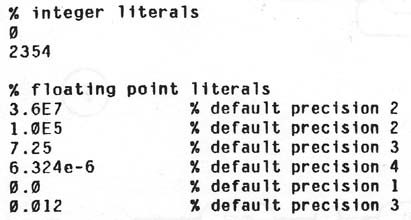
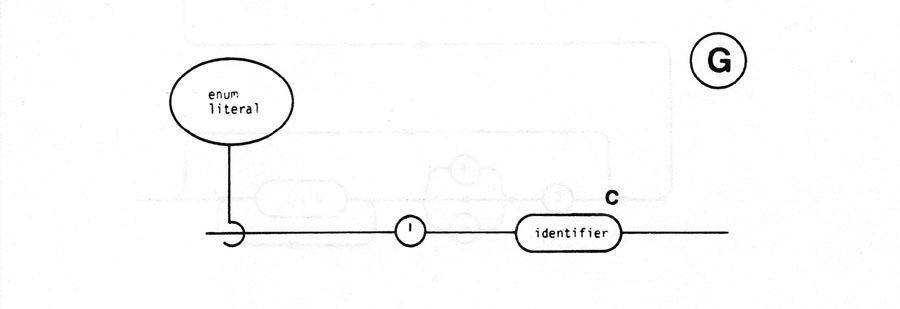
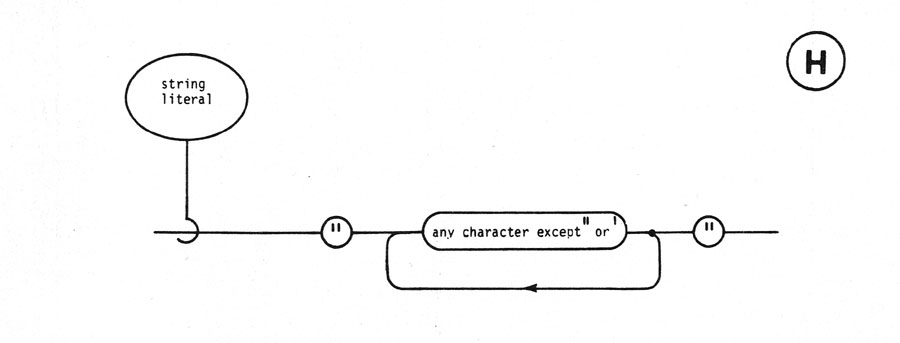
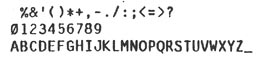A token is the basic component used to build all constructs of the language. It is an indivisible
lexical unit that is interpreted as a complete 'word' by the translator. A token separator is required in
some cases between tokens and can be used otherwise to improve readability. A token or token
separator is composed of a contiguous sequence of characters.
RULES
Input text is organized into lines, each of which is composed of tokens and token separators. No
token or token separator can extend over more than one line of text. An end of line, eol, is a token
separator.
A token separator must appear between any two adjacent tokens, unless one of the tokens is a
special symbol or an operator symbol
(such as < >) which does not have the form of an identifier (e.g.,
AND)). One or more token separators may appear between any two tokens.
EXAMPLES

2.3 TOKENS
2.3.1 RESERVED WORDS
Reserved words have a fixed meaning within the syntax of the language.
RULES
The following are reserved words:

NOTES
Reserved words may not be redefined.
No distinction is made in the user of upper or lower case characters in a reserved word, thus, end,
End, END, and enD are all equivalent.
2.3.2 OPERATOR SYMBOLS
Operator symbols are names of functions which are invoked with a special prefix or infix syntax
(see Section 5.2).
RULES
The operator symbols are:

NOTES
The definition of operator symbol names is discussed in
Section 13.2.
All of the special symbols, except [, ], and #, consist of characters exclusively from the 55-character
set. The following 55-character alternates are provided.




 Copyright © 2009, Mary S. Van Deusen
Copyright © 2009, Mary S. Van Deusen