2. LEXICAL STRUCTURE
2.1 CHARACTER SET
There are two aspects of the character set issue. First, what is the set of
characters which may appear in source programs, and second, how does one deal with
specialized character sets which may depend on devices in the run-time environment?
In this section we consider the first of these questions. For a discussion of the
second, see Sections 3.5 and 3.6.4.
One of the changes from Ironman to Steelman was the reduction of the character
set in which source programs must be capable of being represented. The basic
55-character ASCII subset (hereafter referred to as "Basic 55") required by
SM 2A 1
comprises the 26 upper-case letters, the 1O numeric digits, the space character, and
the following 18 symbols:
% & ' ( ) * + , - . / : ; < = > ? _
The main issue which arises is the following: what is the maximal character
set which may be used in source programs, and what is its relationship to Basic 55?
The following alternatives were considered:
- The two sets are identical; i.e., it is illegal to use any character
outside Basic 55.
- The language defines an extended character set and specifies the
transformation from that to Basic 55.
- The language defines an extended character set transformable to Basic 55,
as in Alternative 2, but also permits additional graphics, possibly device dependent,
for which no transformation is specified.
Alternative 1 was rejected, since Basic 55 is too austere a character set to
impose on all users. At the other extreme, to allow characters in the source text
without the language specifying their representation in Basic 55 (Alternative 3) was rejected
since it violates SM 2A and introduces implementation dependencies. Thus Alternative 2 was
adopted, and we chose the 95 character ASCII subset (hereafter called "95 ASCII")
together with ASCII end-of-line (e.g., carriage-return line-feed) as the extended
(maximal) character set which can be used in source programs. 95 ASCII consists of
Basic 55 together with the 26 lower-case letters and the following symbols:
@ $ [ ] \ " ! # ˆ
‘
{
¦
}
~
This choice was fairly natural, since it comprises the printing graphics from the
character set which has been adopted as a standard by the government.
In the RED language we have attempted to minimize the use of characters outside
the Basic 55 set. In particular, only the square brackets, quotation mark and pound
sign are used.
2.2 CHOICE OF TOKEN STRUCTURE
In this section we justify the lexical conventions adopted for RED and explain
the conversions from 95 ASCII to Basic 55.
2.2.1 INTEGER LITERALS
An integer literal is simply a sequence of digits. Although a "break"
character might seem useful, this was rejected on the grounds of simplicity and
program reliability. The only viable candidates for a break character are the space
and the underscore. The problems with the space are first, that it would be a
different break character than that used in identifiers, and second, that it would
result in the treatment of errors as legal tokens (e.g., 1 2 where the user does not
intend 12). The problem with the underscore is that it is visually too close to the
minus sign. It is a simple error to interchange these characters during the entry
of an integer literal, with the resulting program still lexically, syntactically,
and semantically legal.
2.2.2 FLOATING POINT LITERALS
Floating point literals have a conventional structure; 1.0E-12 and 3.14159 are
examples. A break character for floating point literals was rejected, for
consistency with integer literals. RED requires at least one digit before and after
the decimal point, in the interest of readability.
2.2.3 IDENTIFIERS
The underscore serves as the break character in identifiers. The space
character was considered for this role but was rejected on grounds of simplicity and
readability; e.g., X MOD 3 would comprise three tokens, whereas X NOD 3 would be a
single token. It should be noted that the objections to underscore as a break
character in integer literals do not apply to identifiers, since the error of
entering, say, ABC-DEF instead of ABC_DEF would in all probability be detected by
the translator. (In order for ABC-DEF to be correct, the identifiers ABC and DEF
would have to be known in the scope containing the expression, and their types would
have to be such that the "-" operation can be applied to them, returning a value
whose type is that of the intended identifier ABC_DEF.)
Lower-case letters are permitted in identifiers, and are useful for
readability. One possible programming convention is to adopt upper-case letters for
reserved words and built-in identifiers, and to use lower-case letters for U
programmer-defined identifiers. This convention has been employed for the examples
in the Language Reference Manual and this document; it helps avoid the visual
monotony which can result when only one case is used. Note, however, that no
distinction is made by the translator between upper- and lower-case characters in
identifiers. This is important so that programs which are legal when written in 95
ASCII will still be legal and have the same semantics when converted to the Basic 55
character subset.
The RED language, in compliance with SM 13F, does not impose an upper bound on
the length of identifiers (other than requiring them to fit on one line (SM 2D)).
2.2.4 ENUMERATION LITERALS
Our main motivation was to provide a simple lexical structure to enumeration
literals and to facilitate the use of enumeration types to define character sets (as
required by SM 3-2D). To meet these goals, an enumeration literal in RED comprises
an apostrophe juxtaposed with a sequence of characters which have the form of an
identifier. For example, 'HIGH, 'medium_range, 'X2, and 'CTRL_C are legitimate
enumeration literals.
The leading apostrophe makes enumeration literals lexically distinct from
identifiers; e.g., HIGH (an identifier) is immediately distinguishable from 'HIGH
(an enumeration literal). Strictly speaking, this was not necessary. In Pascal
[JW76], for example, enumeration elements are simply identifiers. However,
providing distinct forms is useful for readability, ease of writing, and language
simplicity. Concerning readability, the program text will more clearly reveal its
intent if data of different types can be readily differentiated. (We note that
existing languages in DoD - e.g., CMS-2 [FCDSSA75] and JOVIAL J73/i [AF77] -
provide such distinguished forms.) Concerning ease of writing, the programmer can
compose enumeration types without worrying about name conflicts with identifiers.
Concerning language simplicity, there is no need to provide a special form for
character literals which appear in enumeration types. The individual enumeration
elements serve as names for character literals, with the latter appearing in string
literals.
The choice of a leading apostrophe as the means for distinguishing enumeration
literals was motivated by the desire to use a character in the Basic 55 subset which
would not visually overwhelm the remaining characters in the literal. For this
reason, the question mark was rejected, and each of the other characters had uses in
the language which would cause either potential confusion or actual ambiguity if
employed as part of enumeration literals.
Lower-case letters may be employed in enumeration literals, with the same
conventions as for identifiers; i.e., the translator does not distinguish lower case
from upper case. Thus, 'A and 'a denote the same literal. (As a consequence, the
enumeration literals representing lower-case letters in the definition of a
character type will have a form such as 'L_A rather than just 'a.)
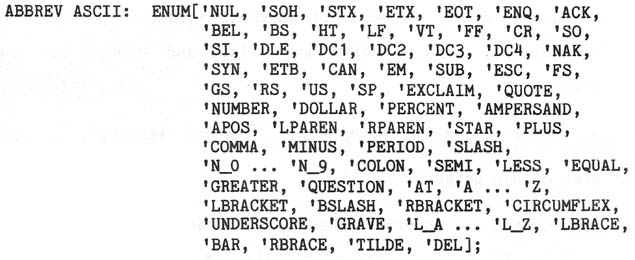
As an example of the use of an enumeration type to define a character set, the
following is the built-in definition of ASCII, representing the 128-character ASCII
set:
2.2.5 STRING LITERALS
String literals in RED comprise sequences of characters delimited by quotation
marks; e.g., "This is a string". Any character from 95 ASCII, except for the
quotation mark and apostrophe, may appear in a string literal. To obtain a
quotation mark, apostrophe, or a control character outside 95 ASCII as part of a
string, the user can catenate onto the string the enumeration literal denoting the
desired character. For example, "{x¦x+y<C}" is a string literal; the string
'FF & "operator intervention required" & 'BEL
would, on output, produce a form feed and the string shown, and then ring the bell
on the output device. Since catenation (&) is a manifest operation (see Section
4.2), no run-time overhead is implied by the use of this technique to build strings
out of string and enumeration literals.
Since string literals can contain characters outside Basic 55, the conversion
of literals into this subset is an issue. The solution is straightforward:
- each enclosing quotation mark is converted into two consecutive apostrophes
(this is why apostrophes are excluded from string literals);
- for each non-Basic-55 character within the string literal, a string escape
(i.e., &) is employed, and the character is replaced by its corresponding
enumeration literal.
For example, "ABcd" becomes "AB" & 'L_C & 'L_D under this scheme. This
transformation is applicable even when the string literal is based on a user-defined
character set. It may be noted that the conversion is reversible; i.e., given the
Basic 55 version, one can construct the corresponding 95 ASCII form. Also, there is
no ambiguity in RED between a string literal of length 1, such as "A", and a
character (ASCII) literal, 'A.
2.2.6 COMMENTS
The comment conventions in RED are simple and are in conformance with SM 2I.
Each comment begins with a percent sign and terminates at the first end-of-line.
Embedded comments are thus excluded, but this was the explicit intent of Steelman,
since the omission of the terminator on an embedded comment can inadvertently cause
the loss of part of the program.
Since comments can use any non end-of-line character in 95 ASCII, the issue of
conversion to Basic 55 arises. For simplicity, the transformation is to replace
each lower-case letter by its upper-case analog, and to replace each other character
not in Basic 55 by a blank.
2.2.7 OPERATOR SYMBOLS
RED provides a conventional set of prefix and infix operators, and the only
issues are with respect to whether mnemonic or symbolic forms should be used.
Modulo and Integer Division
Required by SM 3-1H, these infix operators are realized in RED mnemonically as
MOD and DIV. Although the symbol "/" could have been chosen for integer division,
this was rejected for two reasons:
- MOD and DIV are related operators, and for consistency both should be
mnemonic or both symbolic.
- In many applications it will be desirable to overload "/" such that the
quotient of two INTs returns a FLOAT. Predefining "/" on two INTs to return
an INT will interfere with this goal.
Catenation
The symbol "&" is appropriate for catenation, an operation required by SM 3-3E.
Since catenation will be heavily used in connection with string literals, a short
(one character) symbol is preferable to alternatives such as // or CAT.
Logical and Set Operators
RED provides AND, OR, XOR and NOT for set intersection, union, symmetric
difference, and complement (required by SM 3-4B). An alternative approach, to use
*, +, and - instead of AND, OR, and NOT, was rejected for two reasons:
- A mnemonic operator would still be required for symmetric difference, since
no conventional symbol has this interpretation.
- Expressions involving relations between arithmetic expressions would be
confusing to read if the same symbols were used for both logical and
arithmetic operations.
Relational Operators and Assignment
RED provides the symbols =, /:, <, <=, >, and >= for the relational operators
required by SM 3-1C. The alternative considered was the set of mnemonics EQ, NE,
LT, LE, GT, and GE. Although there are valid arguments for the latter set on the
basis of programmer familiarity (these are basically what FORTRAN supplies), the
decision to adopt symbolic forms was motivated by the following considerations:
- Provided they have commonly understood meanings, symbolic operators are
preferable to mnemonic forms with respect to readability because of the
visual lexical variation which the symbols impart to the program text.
- The relational operator symbols adopted by RED are employed by other
languages in use in DoD; e.g., they are identical to those of SPL/I [NRL77]
and nearly the same as those of TACPOL [Li75] and JOVIAL J73/1 [AF77].
Given the use of "=" for equality, it is natural to provide a different symbol
for assignment (the use of "=" in both contexts leads to error-prone constructs such
as X:Y=Z), and RED follows standard practice in choosing ":=" as the assignment
symbol.
Mnemonic Operators as Reserved Words
One consequence of the choice of operators such as DIV, MOD,-etc., which have
the form of identifiers is that they should be reserved words because of their
syntactic role as delimiters. An alternative is to provide a means for making such
operators lexically distinguished, and thus to avoid making them reserved words.
This alternative was rejected on the following grounds:
- The FORTRAN approach of enclosing the operator between "."s does not work,
because of the ambiguity with dot qualification: X.MOD.Y could mean either
the .MOD. operator applied to X and Y, or the Y component of the MOD
component of X.
- With any other method for providing lexical distinction to mnemonic
operators, the added complexity resulting from the addition of a special
form to the language would outweigh the benefit of reducing the number of
reserved words.
It should be noted, though, that an attempt was made to minimize the number of
reserved words in the language. For example, symbols such as ARRAY, RECORD, and
SET, which are used in type specifications, are not reserved.
2.2.8 SPECIAL SYMBOLS
Square Brackets
Square brackets are used in RED to delimit type properties, translation time
properties, and constructors. The provision of a distinct pair of symbols for these
purposes is quite useful with respect to program readability and language
uniformity. For example, distinguishing "type" vs. "subtype" properties based on
whether square or round brackets appear is an easily remembered convention, with
"square" suggesting "hard" properties which are the same for each object of the
type, and "round" suggesting "soft" properties which may differ from one object to
the next.
Since square brackets are outside the Basic 55 character set, the language
defines conversions to this set; viz., "[" becomes "<<", and "]" becomes ">>".
Pound Sign
The pound sign, "#", is used in RED for explicit literal resolution; e.g.,
'A#ASCII, "2FF"#hex. An alternative which was considered for this purpose is a
functional notation with the destination (sub)type used as a function, e.g.,
ASCII('A). This alternative was rejected for two reasons:
- Allowing a (sub)type to be used as a function requires special rules,
especially if the user is to be able to define and export such a function.
- Potential ambiguities may arise - e.g., is STRING[ASCII](5) a subtype, or
is it the resolution of literal 5 to type STRlNG[ASCIl]? Although the
context of its use may be sufficient for the translator to determine the
meaning, the construct will still be confusing to the human reader.
The Basic 55 version of "#" is the "::" sequence.
End-of-Line
Although Basic 55 does not include any explicit character(s) for end-of-line,
the notion of a source program line boundary is still relevant. Thus source program
end-of-lines, such as carriage-return line-feed sequences, are converted to new line
boundaries in Basic 55.
**************
| 1 |
Throughout this document, the acronynm "SM" refers to the Steelman requirements. |




 Copyright © 2009, Mary S. Van Deusen
Copyright © 2009, Mary S. Van Deusen
