9. ADVANCED AND LOW-LEVEL FACILITIES
9.1 USER-DEFINED ASSIGNMENT
9.1.1 THE NEED FOR USER-DEFINED ASSIGNMENT
In the RED language, an assignment routine is automatically provided for each
new data type, in agreement with Steelman 5F. However, there are two situations
which must be addressed:
- when the new type should in fact not have assignment available, and
- when the new type should have an assignment routine with different semantics
from the one automatically provided.
A "non-assignable" type (i.e., a type for which assignment is illegal) is
easily obtained in RED, either by defining an assignment routine which raises an
exception, or by not exporting the (automatically provided) assignment routine from
the capsule in which the type is defined. In the first case, assignment would raise
the exception even when used in the defining capsule. In the second, assignment
would be allowed inside the capsule but disallowed outside.
RED allows the user to specify an assignment routine for any new type for which
the automatically provided assignment semantics would be inappropriate. Such a
facility, neither required nor prohibited by Steelman1, was included to support data
abstraction. The generality provided by user-defined assignment may be ignored by
those programmers who do not require it; there is no run-time cost incurred when the
facility is not used.
The desirability of allowing user-defined assignment can be seen by examining
some typical applications. Consider a user who defines a data type implementing
queues by a capsule which exports appropriate type and routine declarations. It is
highly desirable, in the interest of maintainability, for the uses of the queue
routines outside the capsule to be independent of the underlying type of the queue
type. In particular, whether queue is defined as a direct type or as an indirect
type should not be ascertainable outside the capsule, since if it is necessary to
change from one to the other during program maintenance the users of the capsule
should not be affected. However, there is an obvious semantic difference between
the built-in assignment for indirect and (say) array types. Since the former
implies sharing and the latter does not, the effect of

depends on whether queue is defined as a direct or as an indirect type. This
problem can be avoided if the user defines an assignment routine for queue which
performs an element-by-element copy instead of a "pointer" copy.
As another example, consider the problem of defining "varying strings" in the
language. A varying string is declared with a value specified for its maximum
length; during its lifetime it may hold string values whose lengths may be between 0
and this maximum length, inclusive. For example,
It is certainly desirable to allow the assignment of one vstring to another,
provided that the cur_length of the source does not exceed the max_length of the
destination. However, the built-in record assignment for vstring would fail for two
reasons:
- If the vstrings had different max_lengths, the string assignment of the data
fields would be illegal, and
- If the vstrings had the same max_length but the source vstring's cur_length
was less than its max_length, then the X_INIT exception could be raised when
the copy of the data field was attempted.
with user-defined assignment, these problems are avoided:

9.1.2 INTERACTIONS WITH OTHER FEATURES
Aggregate Assignment
If the user defines assignment for type T, and T is used as a component in an
aggregate (e.g., an array, record, or union), then the assignment automatically
provided for the aggregate type will invoke the user-defined assignment for T. For
example, if the user declares:

then the assignment
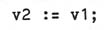
is equivalent to

Analogously, record and union assignment will invoke user—defined assignment
for any component for which such an operation has been provided. Thus, with the
following declarations

the assignment
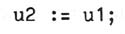
is conceptually equivalent to

Features with "Copy" Semantics
A number of features in the language have "copy" semantics: initialization in
data declarations; CONST and OUT binding in formal parameter specifications; READ
and WRITE input-output procedures; function result returns; message passing via
MAILBOXes. In each case, should the copy invoke the automatically provided (i.e.,
"bit copy") assignment, or, if one is defined for the particular type in question,
the user-defined assignment? If the type is "non-assignable", should the copy be
allowed at all?
In RED, all features with copy semantics are treated consistently with respect
to these questions. The copy always invokes the user-defined assignment (if one is
defined), and is illegal if the type is non-assignable. (Thus CONST parameter
passage is illegal for non-assignable types.) The reasons for adopting this approach
are that
- the use of "bit-copy" would allow the detection of whether the underlying
type were direct or indirect, and
- the behavior expected from the copy is in fact the abstract (i.e.,
user-defined) assignment.
For example, if the user defines a procedure with a CONST parameter declared as a
vstring(20), then it would be counterintuitive to have bit copy assignment when an
actual parameter is passed.
Binding Classes on Formal Parameters to User-Defined Assignment
The ability to define the assignment routine for user-defined types, together
with the fact that CONST and OUT binding invoke the user-defined assignment, imply
that these two binding classes should not be used for the formal parameters to
user-defined assignment routines. Instead, the VAR binding should be used for the
parameter corresponding to the assignment target, and the READONLY binding for the
assignment source. Further discussion of this point may be found in Section 5.1,
where the reasons for providing the READONLY binding class are given.
Exporting Assignment from Capsules
The issue is the following: if a type T is exported from a capsule, must
asssignment for T (whether system- or user-defined) be also explicitly exported, or
is it exported automatically with T? RED requires explicit export of both T and its
assignment operator, in the interest of avoiding unnecessary defaults. Allowing
assignment to be exported automatically with T would be potentially dangerous in
case T was intended as a "non-assignable" type.
9.1.3 OPTIMIZATION ISSUES
As mentioned earlier, user-defined assignment, if not used, will not cause
run-time overhead. Moreover, an attempt was made in the RED design to facilitate
optimization even when user-defined assignment is used. This is not an empty issue,
since, as an arbitrary procedure, a user-defined assignment routine may have
extremely perverse behavior and, if "worst case" assumptions are made, very few
optimizations could be carried out across a user-defined assignment.
The approach taken is to impose a weak restriction on user-defined assignment
and to allow the translator to make certain assumptions about the behavior of
user-defined assignment which facilitate optimization.2
The restriction on a user-
defined assignment routine is that the two formal parameters must be of the same
type. The assumption which the translator may make is that the value of the target
after the assignment is the same (via the user-defined equality operation, if one
has been defined, or the automatically-provided equality operation otherwise) as the
value of the source before the assignment.
1 This is directly analogous to the approach to side effects in functions (see
Section 5.2). The restrictions in this latter case prohibit many (but not all) side
effects, and Steelman HC allows the translator to optimize expressions via
reordering operands independent of whether side effects are reordered as a result.
9.2 USER-DEFINED INITIALIZATION AND FINALIZATION
For any data item there is a set of actions performed when the item is created
and a complementary set of actions carried out when the data item ceases to exist.
(A data item is considered to be created by CONST and VAR declarations, CONST and
OUT formal parameter declarations, function returns, and the allocation statement.
A declared data item ceases to exist when an exit occurs from a scope containing the
declaration; a dynamic variable ceases to exist when any pointer referencing it is
FREEd, or when no pointers reference it.)
The set of actions performed during data
creation is called initialization; finalization is said to occur
when the data item
ceases to exist. In most languages, the user has no control over initialization and
finalization semantics. In many cases, however -- especially in connection with the
definition of abstract data types -- such control is necessary. For example, a user
who defines an abstract type in terms of an underlying indirect type may want
declarations to initialize variables to point to newly allocated dynamic variables,
and scope exit to induce a "cleanup" of dynamic data whose pointers are the values
of local pointer variables. This is especially true in environments where the
system has no automatic storage reclamation -- typical of embedded systems. Another
example of the utility of user-defined initialization and finalization routines is
for metering the use of data. An initialization procedure could keep track of the
number of data items created with given subtype constraints -- e.g., it could
produce statistics on the frequency of use of strings of different lengths.
For the above reasons, and also to comply with the Steelman requirement for
resource control (SM 8E), RED allows the user to
define initialization and finalization routines.
An example of such user-defined routines appears in the Language Reference
Manual, Section 13.3.
9.3 USER-DEFINED SELECTION OPERATIONS
Steelman (SM 3-3F) requires that the user have the ability "to declare
constants and (unary) functions that may be thought of as record components and may
be referenced using the same notation as for accessing record components." To meet
this requirement, and also to satisfy the more global objective of supporting data
abstraction, RED allows the user to define selector operations. For uniformity,
this facility applies not just to "dot qualification" but to subscripting and
subarray selection. For efficiency, user-defined selectors are in fact functions
which return (constant) values; thus their invocations may not be used in contexts
where a variable is required.
Examples of user-defined selectors may be found in Section 3.6.2 of this
document, and in Section 13.4 of the Language Reference Manual.
9.4 MACHINE-DEPENDENT FACILITIES
One of the major objectives of the RED language is to eliminate much of the
need for assembly language programming in embedded systems. To meet this goal, RED
provides a variety of facilities with which the user can perform low-level and
machine-dependent operations. These include features for defining physical
representations for data items, aligning data, storing data at specified machine
addresses, and defining handlers for asynchronous interrupts.
9.4.1 SPECIFICATION OF PHYSICAL REPRESENTATIONS
It is sometimes necessary to process data which have been externally generated
(i.e., whose representations have not been determined by the RED translator). To
accomplish this, the programmer must be able to specify both a high-level
description of the data (i.e., their types), so that the appropriate operations can
be performed, and a low-level definition of the data (i.e., their representations),
so that their values can be correctly retrieved and stored.
An extreme position would be to allow the user to associate multiple
representations with any type; the translator could generate code to perform the
necessary conversions. This level of generality is not necessary, however, and the
implicit inefficiencies which would result are undesirable. In fact, one of the
changes from Ironman to Steelman was the removal of the requirement that the
language allow the definition of multiple physical representations per type.
The RED language complies with the Steelman requirement (SM 11A) for data
representation. The user can specify a single physical representation for a new
type; the interpretation is that each data item of the type will have that
representation. As an example, consider the type declaration:

The declaration comprises the logical properties of t (i.e., the underlying type)
and the physical properties (size, alignment, and component representation). lf x
is declared to be of type t, then x will occupy one halfword, be word-aligned, and
have constituents x.a (3 bits, from bit 0 through 2), x.b (2 bits, bits 3 and M),
and x.c (N bits, bits 12 through 15). Bits 5 through 11 are unused.
Choice of Bit as Storage Unit
Size, alignment, and offset are specified in terms of bits, and the language
defines the bit numbering to start with bit 0 in the leftmost (i.e., high-order)
position. An alternative is to assume the existence of implementation-dependent
storage units (e.g., bytes, halfwords, etc.) for use in representation
specifications and to adopt the bit numbering of the target machine. This
alternative was rejected for several reasons.
- Since the implementation can define manifest configuration constants
reflecting the number of bits per byte, bits per halfword, etc., programs
can make use of these constants in representation specifications. In the
example above, the size of each t data item is one halfword (HALFWORDS is
assumed to be the number of bits per halfword). Thus the implementation
dependency occurs where it is appropriate -- in the value of the
configuration constant, rather than in the language.
- Use of the implementation-defined bit numbering would make programs harder
to read and transport. Although transportability of machine-dependent
programs might not seem to be of high priority, there are occasions where
this is useful, and the language should not adopt implementation
dependencies which defeat this purpose.
Restrictions on Reference Parameter Passing
The components of a data item whose type has a representation specification
will generally have non-standard representations. For example, the translator may
conventionally store INT data as full words, whereas the declaration of type t above
requires an INT (its "a" field) stored in the leftmost three bits of a word, with
other data in the rest of the storage unit. There is no problem when a value is
copied into or out of this component (e.g., when the component is passed as an
actual CONST or OUT parameter or is used as the source or destination of the built-in
INT assignment operation). In such a case, the translator can generate
conversion code which "unpacks" the component into a (standard) INT, or which
"packs" an INT value into the field. However, if the component were permitted to be
passed by reference -- either READONLY or VAR -- substantial inefficiency would
result, since the code accessing the value of the formal parameter would have to
work for non-standard representations such as fields which overlap storage unit
boundaries. As a consequence of these considerations, it is not permitted to pass
READONLY or VAR the components of` a data item whose type has a representation
specification. Note that this restriction applies to ".ALL" components, too. For
example, if x is declared to have type t, then x.ALL has type

but the actual representation for x.ALL will not be the standard one for this type.
Restrictions on Built-In Types
In order for a new type to be declared with a representation specification, its
underlying type must comprise only built-in types and type generators. The reason
for this restriction is that no assumptions may be made about the representation for
data of a user-defined type; i.e., one of the main reasons to define a new type is A
to allow for changes in the underlying type without affecting users of the new type.
It is thus not appropriate to apply a representational item to a component having a
user-defined type.
A related issue concerns enumeration types. Since enumeration literals are not
automatically inherited by new types defined in terms of enumeration types (see
Sections 3.3.4 and 3.5.3), allowing the specification of "collating sequences" for
enumeration literals as part of the representation specification for a new type
would not be too useful. Instead, the user can specify that a standard,
representation be given for the literals in an enumeration type; viz., 0 for the
least element, 1 for the next, etc. This approach avoids certain anomalies which
can arise if the user were to supply a representation with "holes" in it; e.g., the
implementation of arrays indexed by such enumeration types.
Separation of Logical and Physical Properties
The representation specification for a new type is disjoint from its logical
properties (i.e., the specification of the underlying type), in compliance with
SM 11A. It is, however, part of the type declaration form. We considered an
alternative approach with distinct declarations but rejected it for several reasons:
- A type declaration can be parameterized, and the parameters may be used in
the representation specification. It would be semantically anomalous for
the invocation of a type to result in an invocation of a completely separate
entity (the representation). Since the two are invoked together with one
syntactic form, they should be declared with a single syntactic form, with
enough separation in the syntax to allow the reader to distinguish logical
from physical properties.
- Adding a representation specification to a type which previously lacked one
can have a semantic effect (e.g., previously valid VAR or READONLY parameter
passing may become illegal). Removing or changing a representation
specification can likewise have semantic impact (e.g., when fields overlap).
As a result, it is appropriate for the representation specification to be
included as part of the type declaration, where the semantics of the type
are established.
"Dope Vector" Issues
It is often necessary to have arrays in machine-dependent data structures, and
it is important that the user be able to control the storage layout for them. In
particular, the user should be able to determine whether bounds information will be
stored with the array data. (The same issues arise in connection with other
subtypes -- e.g., range bounds for INTs, precision for FLOATs. We will restrict our
attention to the array case with no loss of generality.)
Two situations are expected to arise most frequently in practice: when the
bounds are manifest, or when one or both is an attribute associated with the type.
An example of the first case appeared at the beginning of this section: the "c"
field of t is an ARRAY INT(1..4) OF BOOL. The translator will not store "dope
vector" information at run time, since it can be maintained at translation time. If
the "c" field is used as an actual parameter (only CONST and OUT are possible, since
reference passage of components is prohibited), and the formal parameter is
represented with a run-time dope vector, then the appropriate representational
conversion can be performed at run time on copy-in or copy-out. Thus the
ARRAY INT(1..4) OF BOOL field will in fact fit in A bits, and bounds checking is
still performed on subscripting.
A less frequent but equally important case arises when an attribute associated
with the type is used to specify bounds information. As an example, suppose that a
machine-dependent record is desired with the following format:
- the first byte gives the length of the record (in bytes),
- the second byte is an INT(0..255),
- each remaining byte contains a BOOL in the leftmost bit and an ASCII
character in the remaining 7 bits.
The following type declaration specifies the desired representation:

Since the NOBOUNDS specification is given for the array component, subscript range
checking is not done. E.g., if x is declared to be of type mrec, then before
selecting x.b(i) the user should check that i is less than or equal to x.n-2.
Further examples of machine-dependent representation specifications appear in
Section 12.2 of the Language Reference Manual and
in Appendix B of this document.
9.5 LOW-LEVEL MULTITASKING
There are two motivations for the RED multitasking design:
- The need to provide simple, safe, and efficient high-level mechanisms for
standard applications, and
- The paramount importance of permitting flexible and efficient implementation
of a wide variety of system design paradigms.
The first of these is addressed by the built-in high-level facilities. The second
is addressed by providing means by which new high-level facilities may be defined.
The philosophy is to make available the low-level primitives that are used in
defining the high-level facilities. These primitives can then be used to define
alternative high-level facilities when needed. Alternative methods of sending and
receiving messages, delaying activations, controlling access to shared data, and
scheduling activations can all be defined. In each case a capsule will be defined
which provides one or more new types and associated operations.
The rationale for this philosophy is simply that not enough is known about
multitasking to enforce a single system design paradigm on all parallel systems. On
the contrary, many legitimate paradigms exist, and each of these is better than the
others for certain applications. Furthermore, in any large project, there will be
system designers who are better able to assess the needs of that system than can the
language designers. It is these system designers whom we expect to use the low-level
multitasking facilities to define mechanisms that will be used by the
application programmers. To this end, we have carefully designed the low-level
facilities of RED to smoothly integrate with the high-level facilities; the
application programmers will not need to know whether they are invoking built-in or
application-specific mechanisms.
The integration of high- and low-level facilities is achieved in three steps:
- The definition of the high-level multitasking statements (CREATE, WAIT,
REGION) in terms of semantically equivalent low-level operations,
- The definition of the low-level operations on the built-in types, and
- The addition of a small number of additional low-level operations (e.g.,
CRITICAL) and types (e.g., LATCH).
For example, Section 10.5 of the Language Reference Manual defines the
semantics of the WAIT statement. The definition is given as a semantically
equivalent expansion into a sequence of RED statements and routine invocations. The
routines invoked in this expansion are low-level routines that operate on data of
MAILBOX type. To define alternative methods of sending and receiving messages, and
of delaying execution (e.g., for some length of simulated time), one only needs to
define new types. (These types will normally be defined as abstract data types (and
operations) within a capsule.) The defining capsule must provide the operations used
in the elaboration of a WAIT statement. This is done by defining a subtype and four
additional routines for each operation intended to be so used. The subtype and the
four operations are used in the WAIT statement when the associated waiting operation
appears in a clause. In the definition of the waiting operation, various low-level
primitives such as SYNC_SIGNAL will be used. The example in Section 14.3.1 of the
Reference Manual illustrates how mailboxes can be implemented.
Alternative methods of locking can be obtained through the definition of a new
type with operations named LOCK and UNLOCK. These operations will be invoked during
elaboration of the (expansion of) the REGION statement. The example in Section
14.4.1 of the Reference Manual shows how monitors can be defined in RED.
Users can define new schedulers by providing a new activation type with
operations for starting, ending and synchronizing activations. Sometimes, a task
definition for the scheduler of activations of the new type must also be provided.
The example in Section 14.5.4 of the Reference Manual shows how a round-robin
scheduler can be defined.
In addition to the primitives used in defining alternatives to high-level
multitasking facilities, RED also provides some low-level features intended to be
used in special circumstances. For example, interrupts can be handled by
associating a particular interrupt with a mailbox. Latches (low-level alternatives
to datalocks) can be used when access to hardware-provided mutual-exclusion
primitives (e.g., test-and-set) is needed. The CRITICAL and NONCRITICAL operations
can be used to ensure that preemption does not occur for (brief) periods.
All of the above facilities can, of course, be misused -- just as any well-
intentioned feature of a language can be misused. However, the way in which the
low-level facilities of RED have been designed, and, in particular, the way in which
they may be used to augment the built-in high-levelfacilities, should improve
program clarity, correctness, and maintainability. The alternative approach, that
of providing a single, rigid multitasking facility, will lead to contorted program
structures in those cases where the facility is inappropriate to the most natural
application-induced program structure. Given the present state of knowledge about
parallel programs, there are likely to be a large number of these applications.
The RED multitasking philosophy is precisely the same philosophy that leads to
the notion of data abstraction. Since it is not feasible for a language to provide
all of the data types appropriate to all applications, we provide
- A basic set of types that are frequently used, and
- A mechanism for defining new types, for associating operations with them,
for hiding the details of their implementation, and for creating and
manipulating these types in the same high-level manner as is used for built-
in types.
This is precisely what RED has done for multitasking, and for the same reasons.
9.6 LOW-LEVEL INPUT/OUTPUT
Steelman 8A requires that all
high-level I/O be definable within the language.
RED already has mechanisms for specifying the exact representation and placement of
data, and for handling interrupts. Thus, the only remaining requirement is the
ability to execute any of the primitive I/O instructions defined by the hardware.
This ability is provided by appropriate overloadings of the procedure
LOW_IO(device, command, data);
Typically, the device argument would be an integer channel number or bus address.
The command argument could be an enumeration element designating the I/O instruction
to be executed. The data argument might be a value to be transmitted, or a buffer
to be filled.
***********
1
The prohibition against implicit type conversion (Steelman 3B) implies that both
parameters to the assignment routine must have the same type. This restriction is
imposed by RED on user-defined assignment as well as being true for the built-in
types.
2
This is directly analogous to the approach to side effects in functions (see
Section 5.2). The restrictions in this latter case prohibit many (but not all) side
effects, and Steelman 4C allows the translator to optimize expressions via
reordering operands independent of whether side effects are reordered as a result.




 Copyright © 2009, Mary S. Van Deusen
Copyright © 2009, Mary S. Van Deusen
