5. PROCEDURES AND FUNCTIONS
5.1 FORMAL PARAMETER BINDING CLASSES
Steelman 7F explicitly calls for three binding classes: input, input-output,
and output. The RED language satisfies the Steelman regarding the input-output and
output classes but provides two binding classes for input (CONST and READONLY). The
reasons for our decision will now be explained.
5.1.1 INPUT BINDING ALTERNATIVES
Steelman 7F states that formal input parameters shall "act as constants that
are initialized to the value of corresponding actual parameters at the time of
call." The fact that the formal parameter is to act as a constant implies that it
may not be used in contexts where it could be modified -- i.e., it may not be used
as a target of an assignment nor as an actual output or input-output parameter to
another routine. Within this constraint there are three possible choices for
language semantics: "copy", "ref", and "don't care". To explain these, we assume
that routine R has a formal input parameter F, and that A is the actual parameter
supplied at an invocation.
With "copy" semantics, the effect of the input binding is that A is copied to F
on entry to R. Note that this does not imply that the implementation must be by
copy. If A is a large object and the compiler can verify that A cannot be changed
during the elaboration of R, then A may be passed by reference as an optimization.
We discuss later how often one might expect such an optimization to be realizable in
practice.
With "ref" semantics, the effect of the input binding is that the formal
parameter F refers to the same data object as A. Thus, although F may not be
changed directly, it is possible that F could be changed "indirectly": e.g., a
parallel task could assign to A, or R could invoke a routine which assigns to A. F
has the semantics of a "readonly" variable in such cases. Note that a compiler
could choose to implement "ref" semantics by copy (as an optimization) if it can
verify that A cannot be changed during elaboration of R. The practicality of such
an optimization will be addressed later.
With "don't-care" semantics, the compiler is free to choose either copy or
reference implementation. However, the semantics of some programs will be
implementation-dependent.
5.1.2 IMPLEMENTATION DEPENDENCIES WITH "DON'T CARE" SEMANTICS
Example 1:

Consider the call R(A). If F is implemented by copy, then the invocation of Q from
R will modify A but will have no effect on F. Thus the WRITE routine will output
"COPY". Alternatively, if F is implemented by reference, then the invocation of Q
will have the effect of modifying both A and F. Thus the WRITE routine will output
" REF".
An analogous implementation dependency with "don't care" semantics can arise in
connection with multitasking. For example, a variable A passed as an input
parameter to a routine R may be modified by a task T which is concurrent with R. If
synchronization is carried out so that T modifies A after A is passed to R but
before A is accessed by R, then the value obtained when R accesses A will depend on
whether A is passed by copy or by reference.
The implementation dependencies inherent in the "don't care" semantics rule out
this choice for the input binding class. Thus the alternatives are either "copy"
semantics, "ref" semantics, or both. We now examine these alternatives.
5.1.3 "COPY" SEMANTICS
Suppose that the input binding has "copy" semantics. There are four
substantial problems which arise: inefficiency on passing large objects,
interaction with user-defined assignment, anomalies with nonassignable types, and
interaction with multitasking.
The inefficiency on passing large objects is the most severe of the problems.
Suppose a procedure R takes a formal parameter which is a large object. A "smart" compiler
will attempt to optimize a call on R so that "ref" passage will be
performed. Unfortunately, it is doubtful whether this optimization can be performed
in enough cases to be significant in practice. In order for the compiler to choose
a ref rather than copy implementation for the invocation R(A), it must guarantee
that the object denoted by A cannot be modified during the elaboration of R.
Consider the following situations:
- A is a VAR parameter to a procedure P (i.e., the invocation R(A) occurs
within P's body). This cascading of routines is not an unusual occurrence,
since it arises naturally with "top down" programming. However, in order to
optimize the call R(A) from copy to ref, the compiler must guarantee that
none of the actual parameters to P can be modified during elaboration of R.
i.e., each call on P must be inspected. If P is separately compiled (again,
a case which one would expect to arise frequently in practice), there is no
way to carry out this checking.
- A is a dynamic variable (i.e., it is a "dereferenced pointer"), a frequent
situation in practice. Given the potentiality for sharing via indirects,
the copy to ref optimization will almost never be possible.
- R(A) is invoked from a task to which A is global. This is not an unusual
situation in multitasking environments. Again, the copy to ref optimization
is prevented, since A may be changed while R is being executed, with
synchronization guaranteeing that R sees the "new" A if passage is ref.
Interaction with User-Defined Assignment
The second problem with providing a single input binding class with "copy"
semantics concerns user-defined assignment. (The justification for allowing
user-defined assignment is given in Section 9.1) If the user intends to define the
assignment operation for a type T, what binding should be supplied for the formal
parameter corresponding to the source (i.e., the "right hand side") of the
assignment? It must be an input parameter, since the source of an assignment is not
in general a variable, but note that "copy" semantics for a parameter of type T
implies invocation of the user-defined assignment for T if one is provided, rather
than the "bit-copy" assignment (see also Section 9.1).
Thus an infinite recursion
would result any time assignment on T's was performed! The only way to avoid this
situation without imposing an ad hoc restriction is to supply a "ref" input binding
class instead of, or in addition to, the "copy" input binding class.
Anomalies with Nonassignable Types
It is appropriate for some data types (e.g., DATA_LOCK) to be "nonassignable"
-- i.e., for no assignment procedure to be available. (This can be easily achieved
in RED, as shown in Section 9.1.1.)
Recall, however, that "copy" semantics imply an
invocation of the user-defined assignment routine. Thus, any attempt to pass a
value of a nonassignable type as an input parameter would fail. This would clearly
be an undesirable situation, but is easily avoided if a "ref" input binding class is
available.
Interaction with Multitasking
There are many useful applications of multitasking in which several tasks must
share the same actual input parameter. If the only input binding class was by
"copy", circumlocution would be required to achieve this behavior (e.g., through the
use of an indirect type). A "ref" input binding class obtains the desired effect
directly.
5.1.4 "REF" SEMANTICS
The preceding discussion implied that a single input binding class with "copy"
semantics was unacceptable. Let us now consider the case of a single input binding
class with "ref" semantics. There are three substantial problems which arise:
inefficiency on passing small objects, unsafety, and anomalies with respect to
multitasking.
Inefficiency with Small Objects
The issue of passing small objects has two aspects. The first concerns
"packed" data. If a formal parameter is a BOOL with "ref" input binding, must the
routine be compiled to accept an actual parameter which is "packed" -- i.e., which
is situated at an arbitrary position within a storage unit? In RED, the answer to
this question is "no", since "packed" data components may not be passed by
reference. Thus the problem of passing "byte pointer" information is avoided.
The second inefficiency in passing small objects is not so easily solved. This
concerns the fact that "ref" semantics implies an indirect reference at run-time.
If an INT or other one-word datum is passed, it would be more efficient to copy the
actual parameter and have direct reference to the value, than to go through a level
of indirect addressing at each reference. Unfortunately, if the compiler wanted to
perform the optimization of implementing the call by "copy" instead of by "ref", it
would have the same difficulty (in guaranteeing semantic invariance) as was
discussed earlier in connection with the "copy" to "ref" optimization for large
objects. That is, in practice, the optimization would not often be performable.
Safety Problem
In addition to the efficiency problems, there are reliability drawbacks if the
only input binding is by "ref". In particular, there is no guarantee that the
formal parameter remains constant through the invocation of the routine. A called
procedure or a parallel task may modify the actual parameter, with the. change
unbeknown to the original routine. This drawback by itself rules out the selection
of "ref" semantics as the only input binding.
Multitasking Anomalies
The other problem with "ref" semantics -- multitasking anomalies -- concerns
the lifetime of expression results. In order to avoid "dangling references" the
language must require that the scope of any object passed "ref" to a task T is to be
at least that of T itself. Suppose that the only input binding class has "ref"
semantics, and that T takes an input parameter. Is it permissible to pass an
expression to T? If so, the only possible implementation is to copy the expression
result into a data region reserved for T's activation, since this result cannot be
assumed to persist in the scope in which T is activated. (For example, the
activating scope may terminate before T does.) But it would be somewhat strange for
the semantics of "ref" input to be that of "copy" input when the parameter is to a
task instead of a routine. As a result, it is more reasonable to prohibit arbitrary
expressions from being passed as "ref" input parameters to tasks. (Variables and
constants -- i.e., named data items and their components -- may be passed "ref"
input to tasks, subject to the scope rule mentioned at the beginning of this
paragraph.) Once this approach is taken, however, it becomes mandatory to supply an
additional input binding class with "copy" semantics. In the absence of such a
provision, the only way to pass an expression to a task is through circumlocution:
one would have to declare a variable whose scope was at least that of the task in
question, then assign the expression to the variable and pass the variable to the
task.
5.1.5 CONCLUSIONS REGARDING INPUT BINDING
In summary, our conclusions regarding the input binding class are as follows:
- "Don't care" semantics is unacceptable because of implementation
dependencies which result.
- "Copy" semantics is necessary for safety, and also for efficiency with
respect to avoiding unnecessary indirect referencing.
- However, "copy" semantics is not sufficient, in the light of the need for an
efficient means of passing large objects as input parameters, for an input
binding class which may be applied in user-defined assignment routines, and
for allowing values of nonassignable types to be passed as input parameters.
- Therefore, both "copy" and "ref" input binding classes should be provided.
In RED, the CONST binding class has "copy" semantics, and READONLY has "ref"
semantics.
5.1.6 INPUT-OUTPUT BINDING
Steelman 7F states that formal input-output parameters shall "enable access and
assignment to the corresponding actual parameters, either throughout execution or
only upon call and prior to any exit." Analogous to the input case, there are three
choices for language semantics: "ref", "copy-in, copy-out", and "don't care".
The "don't care" alternative is ruled out for the same reason as in the input
case -- the implementation dependencies which can arise.
The "ref" alternative is necessary to allow large objects to be passed
efficiently (and also to have as a binding class for the target of a user-defined
assignment routine). The problem of passing "packed" data input-output is avoided,
since such data may not in general be passed to formal "ref" parameters.
Although "copy-in, copy-out" is potentially more applicable in certain cases
than "ref", the gain is not sufficient to justify an additional binding class for
input-output parameters. As a consequence, RED provides a single binding class for
input-output parameters, the VAR class, with "ref" semantics.
Note that it is possible to obtain the effect of "copy-in, copy-out" via "ref":

5.1.7 OUTPUT BINDING
Steelman 7F states that formal output parameters' "values are transferred to
the corresponding actual parameter only at the time of normal exit." The choices,
again, are "copy out", "ref", and "don't care".
The implementation dependencies of the "don't care" case preclude this
alternative.
The choice of "ref" semantics would also be inappropriate -- first, the effect
would be identical to "ref" input-output, a binding class already provided, and
second, it would not satisfy the requirement that the value be transferred only at
normal exit. That is, at abnormal exit "unassignment" would have to be performed
for each output parameter, requiring the original value to be saved (i.e., copied!)
before the procedure's invocation.
The "copy out" semantics match the Steelman requirement most closely. As a
consequence, RED provides a single output binding class, the RESULT class, with
"copy out" semantics. Consistent with the "copy" semantics for the input binding
class, "copy out" will invoke the user-defined assignment routine (if one is
provided) for the type in question. No value is transferred from the actual RESULT
parameter to the formal when the procedure is invoked, implying that the X_lNIT
exception will be raised at procedure exit if the formal parameter is never set.
It may be noted that the output binding class required by Steelman is
redundant, in that its effect can be obtained through "ref" input-output. Consider:

Thus, if it is desired to satisfy the intention of Steelman that there be only three
binding classes, we would recommend that CONST (copy-in), READONLY, and VAR (ref
input-output) be retained, and that RESULT (copy-out) be eliminated.
5.2 SIDE EFFECTS IN FUNCTIONS
There are two extreme positions which can be taken with regard to the behavior
of functions:
- Functions are unrestricted in their side effects (i.e. a function is
simply a procedure which returns a value).
- Functions are restricted so as to be "mathematical" in nature -- i.e., if a
function is invoked twice with the same actual parameter values, the result
of the first invocation may be used in place of the second.
Any language decision in this area must face difficult tradeoffs among simplicity,
applicability, run-time efficiency, program readability, and formally specifiable
semantics. For example, A is the simplest approach and obviously would allow any
of the side effects necessary for the application area (e.g., instrumentation and
storage management), but it severely impairs program readability and requires a
tradeoff between efficiency and well-defined semantics in connection with order of
evaluation in expressions. That is, if the order of evaluation is not specified,
the translator has maximal flexibility in generating efficient code, but the choice
it makes may affect the result of the computation. (A good example of this is the
expression pop(stack) - pop(stack). If the top two elements of stack have values 2
and 1, then the subtraction may return either 1, -1, or 0, depending on which order
is chosen and whether "common subexpression elimination" is performed. Also,
depending on how many times the pop function is actually elaborated, either both,
one, or no values might be removed from stack.) Alternatively, if the language
dictates the order of evaluation (e.g., left-to-right), the language semantics
become firm but at a potential loss of run-time efficiency.
With the more conservative approach to functions (B), there is no problem with
either efficiency or well-defined semantics. Since a function invoked twice with
the same actual parameter values always produces the same result and never affects
data external to the function, there is no need for the language to specify a
particular evaluation order for expressions. Moreover, the absence of side effects
in functions helps program readability. The difficulties with (B) are primarily in
connection with language applicability and simplicity. Regarding applicability, it
is sometimes necessary to instrument a function (e.g., assign to a global variable
which counts the number of invocations) or to invoke the allocation statement in a
function; both would be prohibited under (B). Regarding simplicity, since it is
algorithmically impossible for the translator to decide whether a given function
invocation will have a side effect, the language must, if it is to realize (B),
establish a sufficient set of conditions which will guarantee the absence of side
effects. The problem is to make these restrictions simple to state but as weak as
possible while still preventing side effects. But side effects can occur through a
variety of causes; e.g.,
- assignment to formal VAR and OUT parameters
- assignment to imported variables
- assignment to dynamic variables (i.e. pointer dereferences)
- invocations of procedures which have side effects
Although it is possible to formalize a set of constraints which eliminate the above
cases (as in the Phase 1 RED design) an unacceptable amount of complexity would
result. For example, the language would have to carefully distinguish between those
procedures which could legally be invoked from a function, and those which could
not. (It should not be illegal if a function invokes a procedure whose sole side
effect is to modify a variable local to the function.) Moreover, there are a large
number of "boundary" cases whose legitimacy in functions would be difficult for the
user to remember. Is the activation of a task considered a side effect? How about
the invocation of I/O routines or FREEing a pointer?
Since neither (A) nor (B) by itself is acceptable, we must look for a compromise.
This is consistent with Steelman NC: "The language shall attempt to minimize side
effects in expressions, but shall not prohibit all side effects." The approach
adopted in RED is to provide two categories of functions: normal functions, which
have some restrictions on their behavior in the interest of minimizing side effects,
and abnormal functions, for which no restrictions exist. The translator is free to
optimize invocations of normal functions via "common subexpression evaluation" --
thus there need be only as many elaborations of a normal function as there are
invocations of the function with different sets of actual parameter values. Note
that this optimization applies not just within an expression but across statement
boundaries as well. On the other hand, a function marked as abnormal is guaranteed
to be elaborated each time it is invoked, even if the actual parameter values have
not changed. A good example of an abnormal function is a random number generator,
which has no formal parameters and which imports and modifies the seed and returns
the new value as its result. It should be noted that an abnormal function is
analogous to an abnormal data item (e.g. a real-time clock) whose semantics require
each data access to be from the variable's memory location instead of from a
"temporary" location such as a register.
The restrictions on normal functions were chosen so as to be simple to
describe, easy to check (both by the reader and the translator), strong enough to
prevent some of the more dangerous situations which can arise through side effects,
but weak enough to allow the side effects required by SM 4C (i.e., modifications to
own variables of encapsulations). Restrictions on parameter passage disallow one
way of modifying nonlocal variables. The remaining restrictions ensure that any
variable imported into a function declaration is indeed a local variable of a
capsule containing the function definition, and that invocations of the function
cannot occur in any scope in which the declaration of such a variable is known.
It should be realized that the restrictions on normal functions do not prevent
such functions from having side effects beyond the "beneficial" ones of modifying
own variables. Why did we not attempt to strengthen the rules for normal functions,
especially since abnormal functions can be used if side effects are required? The
main reason is language simplicity. Recall the discussion earlier in connection
with B: any restrictions strong enough to prohibit all side effects will either be
overly complicated and ad hog , or so stringent as to prevent large classes of
functions which do not have side effects. Since it is thus unrealistic to try to
provide restrictions which eliminate all side effects, the question is where to draw
the line. But now that we have allowed normal functions to have some side effects,
why do we also provide abnormal functions with unlimited side effects? The answer
lies in the semantic difference between normal and abnormal functions -- abnormal
functions are guaranteed to be elaborated at each invocation, whereas normal
functions can be optimized for common subexpression elimination. The choice of
whether a function should be treated as normal or abnormal can only be made by the
programmer. As soon as the language allows functions to have side effects (even the
limited side effects permitted for normal functions), semantic differences can occur
based on whether a function invocation is optimized for common subexpression
evaluation, and there is no way for the translator to deduce the user's intention.
Thus RED provides two classes of functions. Moreover, since abnormal functions are
guaranteed to be elaborated at each invocation, there is little point in restricting
their behavior; thus the language allows them to have unlimited side effects. In
this area we have apparently violated the requirement in SM NC that side effects be
limited to own variables of encapsulations, but it is questionable whether some of
the side effects required by Steelman (e.g. the ability to perform allocation of
dynamic variables) meet this qualification.
The RED language does not specify the order of elaboration of function
invocations within expressions. This is as required by SM 4C ("The order of side
effects within an expression shall not be guaranteed") and SM 11F ("Except for...the
occurrence of side effects within an expression, optimization shall not alter the
semantics of correct programs..."). An alternative which we considered was to
constrain expression evaluation to be left-to-right if an abnormal function could be
invoked (directly or indirectly) from the expression. However, such a restriction
would be to no avail, since it is possible through normal functions alone -- even
normal functions restricted so that their only side effect is to modify own data of
an encapsulation -- to cause evaluation-order-sensitive semantics. For example,
consider a capsule with two own data items: a table (an array of integers), and an
index into the table reflecting how many entries are present. The capsule defines
and exports a lookup function which, given an integer parameter, searches the table
for its position (inserting it if it is not there) and returns as its result the
product of the actual parameter and the index of its position in the table:
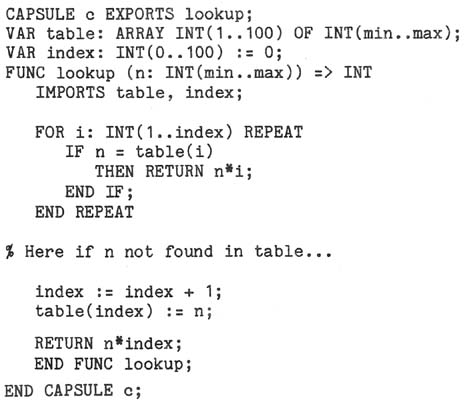
Note that lookup is a normal function which meets the criteria of SM 4C; its only
side effect is to modify data own to the capsule, and it will always return the same
result when given the same actual parameter. However, the value of the expression
lookup(10) + lookup(20)
will be 10*1 + 20*2, or 50, if elaboration is left-to-right, and 20*1 + 10*2, or 40,
if right-to-left.
It is worth pointing out that the notion of whether a function has a side
effect is independent of whether it is normal or abnormal. For example, a normal
function may have side effects (consider the lookup function above, or a function
which keeps a count of the number of times it is invoked). On the other hand, an
abnormal function need not have side effects. A typical example is a parameterless
function whose result depends on the values of imported variables.
In summary, the RED rules regarding functions comply with most of the Steelman
requirement SM 4C. Side effects of a restricted nature are permitted within normal
functions, and the translator ensures that these restrictions are met. The allowed
side effects include the ability to modify an own variable of an encapsulation.
Unrestricted side effects are permitted within abnormal functions, distinguished
syntactically from normal ones by the presence of the keyword ABNORMAL. The
semantic distinction between the two kinds of functions is that the translator
guarantees the elaboration of each invocation of an abnormal function, whereas it is
free to reuse the result of an invocation of a normal function if the values of the
actual parameters have not changed. There is no guaranteed order of evaluation in
expressions (and hence no guaranteed evaluation order for actual parameters to
routines), other than for the "short circuited" AND and OR operations.
5.3 ALIASING
5.3.1 SHARING AND ALIASING
Sharing exists when two referencing forms designate the same data item, or one
designates a component of the other, at the same time. For instance, subscripted
variables a(i) and a(j) share the same data item when i=j; similarly, pointer
dereferences p.ALL and q.ALL share when p and q refer to the same dynamic variable.
Sharing only has detectable effects on a program's behavior when the value of
the shared data item can change. (If the value is constant, then the referencing
forms could designate different data items having the same value and the semantics
of the program would remain unchanged.) The value change typically occurs through an
assignment to one of the variables, which has the implicit effect of changing the
value of the other. A referencing form can designate different data items at
different times: a(i) represents different array elements as the value of i
changes; p.ALL refers to different dynamic variables as p is assigned new values.
This fact makes general sharing a useful semantic component. of any programming
language. For instance, if all sharing were forbidden, many varieties of array
sorting would be illegal. However, the existence of sharing often makes program
understanding more difficult because of the non-obvious nature of the modification
to the data item not directly denoted in the assignment.
Aliasing is a special case of sharing where the two referencing forms are
simply identifiers. An example of aliasing is the case of a data item appearing
twice in an actual parameter list and being bound to two VAR formal parameters; the
formal parameters are aliased. Note that the two cases in the sharing example at
the beginning of this section do not represent aliasing. Furthermore, p and q are
not aliases, either (unless they designate the same pointer data item).
In contrast with general referencing forms, over its lifetime an identifier
always designates the same data item. Aliasing rarely serves to increase the
semantic power of a program. This makes aliasing considerably less useful than
general sharing. Furthermore, aliasing tends to obfuscate the meaning of a program,
and is often the result of a programming error. This has led some languages (e.g.,
Euclid) to place restrictions on programs in the interest of minimizing or
eliminating the possibility for aliasing.
5.3.2 CREATING ALIASES
Unlike some languages (e.g., ALGOL 68), RED does not have a construct for
directly creating aliases. The only way that an identifier x can come to designate
an already existing data item is when the item is an actual parameter which becomes
bound to the formal parameter x having binding class VAR or READONLY. If the data
item is originally designated by y and y is known in the scope of x, or the same
item is also passed to the VAR or READONLY formal y, then x and y are aliased.
As was mentioned earlier, aliasing (sharing) is only noticeable when the shared
data item's value can change. We will narrow our focus to just these cases with the
further restriction that the change occurs due to some action performed on one of
the identifiers, hereafter termed dangerous aliasing. Without loss of generality,
we will not consider the case of one identifier designating a component of the item
designated by the other.
There are only three basic methods by which dangerous aliasing can arise in
RED, all involving "by reference" parameter passage.
| . |
X's binding class |
condition |
| 1) |
VAR |
y is a VAR or READONLY formal;
x and y are passed the same data item. |
| 2) |
VAR |
y is inherited by x's scope;
y's designated item is passed to x. |
| 3) |
READONLY |
variable y is imported into x's scope;
y's designated data item is passed to x. |
In cases 1 and 2, changes can occur via x or (sometimes) y; in case 3, changes can
occur only via y.
5.3.3 ALIAS DETECTION BY THE TRANSLATOR
The translation time detection of aliasing is a formally undecidable problem.
For example, an invocation p(a(i),a(j)) will create aliasing if and only if i=j --
determining at translation time if i=j is known to be undecidable.
However, it is possible to discover potential cases of aliasing at translation
time, with the amount of accuracy depending on the effort expended. The inaccuracy
involves either "detecting" aliasing when it cannot actually occur, or failing to
detect aliasing when it can.
Another possibility is to perform runtime checks for aliasing. This is
theoretically simple but computationally expensive, particularly in the presence of
separate translation, or in checking for aliasing involving a data item and a
component.
5.3.4 RED APPROACH
Steelman 7I requires some restrictions on aliasing. The purpose is clearly to
reduce errors arising from unintentional aliasing, while permitting usage of
intentional aliasing such as through indirects (pointers).1
Our approach is that warnings will be issued during translation for all cases
of potential aliasing, thus notifying the programmer of all aliasing instances which
were not intended. RED supplies a pragmat so that individual warning messages can
be suppressed. This serves two functions. If the translator flags an invocation as
a potential source of aliasing and the programmer can verify that such aliasing
cannot occur, then the warning can be suppressed for that particular invocation. If
the programmer is using intentional aliasing or has verified that the routine is
robust enough to perform correctly in the presence of aliasing, the warning can
likewise be suppressed. In the second case, the pragmat can be applied to the
routine's declaration, signifying that the warning is to be suppressed for all
invocations of the routine. Furthermore, the pragmat serves to notify anyone
maintaining the routine that changes should not be made which are sensitive to
aliasing. The RED approach satisfies the spirit of Steelman in that unintended,
potentially erroneous aliasing is prevented (by warning the user of its possible
occurrence), and intentional aliasing is allowed. Any approach which attempted to
forbid one class of aliasing but permit another would result in unnecessary language
complexity and would meet neither the intent of Steelman nor the needs of the user
community.
**************
| 1 |
Our definition of aliasing differs somewhat from that of Steelman. In
particular, formal parameters having binding class OUT can never be aliased, since
they are newly created on routine entry. The concern of Steelman is for the passage
of the same actual variable to two OUT formals, x and y. ln this case the value of
the item after routine exit would depend on the order in which the assignments of x
and y to the variable occurred -- a potential source of error. The RED approach for
this case is the same as that employed for aliasing.
|




 Copyright © 2009, Mary S. Van Deusen
Copyright © 2009, Mary S. Van Deusen
